但し、
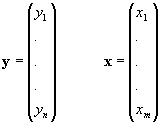
m: 因子の数
n: 推定したい結果
| 統 計情報の評価 − データに惑わされないために |
| 統計結果
から、喫煙は癌の原因になっているとか、いないとか、そういう議論を目にすることは多い。しかし、こうした統計による議論には多少なりとも罠があ
り、結局は読者が自分で正当性を判断しなければならないことが多いと思う。ここでは、そのような統計による議論を読むときに知っておくべき基本事項を整理
してお伝えする。 予備知識だけなので、興味のある方は、成書をお読みください。 |
| 項目 |
日付 |
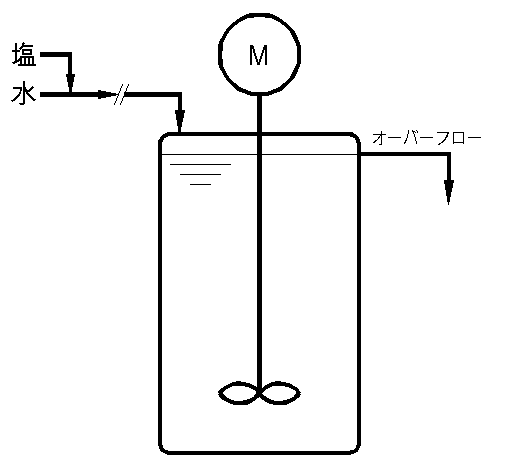
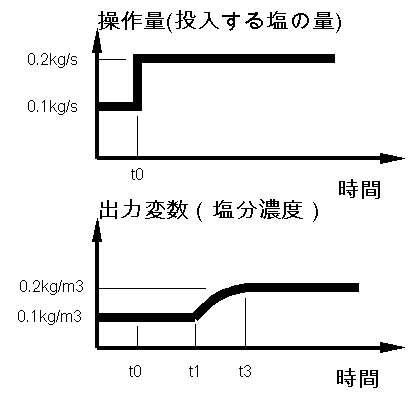
| 時間にずれのあるデータ及び 過渡特性のあるデータの取扱について | 2005/04/10 |
| 最適化について |
2004/06/16 |
| デー
タに基いた数式モデル |
2003/07/26 |
| 相関係数と決定係数 |
2004/01/18 |
y=Fxこのとき、入力変数が変化すると出力変数のうち一つ以上がが変化する。一つも変化しない場合は、その入力変数は出力変数のどれとも無関係ということになる ので、その場合は、不要な変数ということになり、それは、入力変数リストから削除しても良い。しかし、出力変数のどれか一つが変化するのであれば、その数 式モデルの入力として扱うことができる。
但し、
m: 因子の数
n: 推定したい結果
| 入力変数 |
出力変数 |
| 本人の喫煙率 配偶者の喫煙率 本人の1日当りの喫煙本数 配偶者の1日当りの喫煙本数 喫煙期間 |
肺癌の発生率 |
y = f(x1,...,xm)ここで、入出力を結びつける函数fは、どのような形であるかは分からないが、データがあればこのような関係を数式化する方法は複数提唱されている注 2ので、取り敢えず何らかの形で求められたとする。すると、各物質の影響度は、各入力変数軸での傾き(偏微分係数)で評価することができる。 この傾きが一定であれば、それらは線形(比例)関係にあり、一定でなければ、非線形の関係である。そして、この数式は、肺癌発症の可能性を評価するとな る。
| ショートコラム−統計情報を利用して故意に誤解させる 例えば、喫煙率と肺癌の発生率を関係付けようとして、肺癌の発生と喫煙率には関係が無いという結論を導きたい人々が居る。彼らの論調は、"喫煙率が下がり つづけているのに肺癌の発生率は逆に増えている。だから、喫煙と肺癌とは関係がない。"という単純なものが殆どである。この議論のおかしい点は、入力変数 をただ一つに限定しているところである。このように一つだけを取り出して、結論を導くのはいわゆる詭弁であって物事の本質を捉えていない。 この例で云えば、最重要因子と考えられる、煙草に含まれる化学物質の総摂取量が抜けている。即ち、未成年喫煙率が増加していることと、煙草の販売本数が増 えていることは、意図的に隠して論じているのである。未成年喫煙率が上がれば それだけ喫煙者本人の総摂取量は増え、また、販売本数が増えればそれだけ、受動喫煙による、本人の意図しない摂取が増えてしまうというようなことを隠した いときにこのような方法を用いる。 こういった、騙しには、日頃から気をつけたいものである。 |
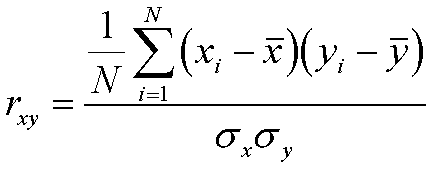
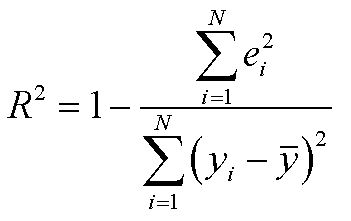
| 目次 |
HOME PAGE |
日本語メインページ |
| その他の主張集 |
禁煙スポットを応援しよう |
伝言版 |